首先上图(非常细致):
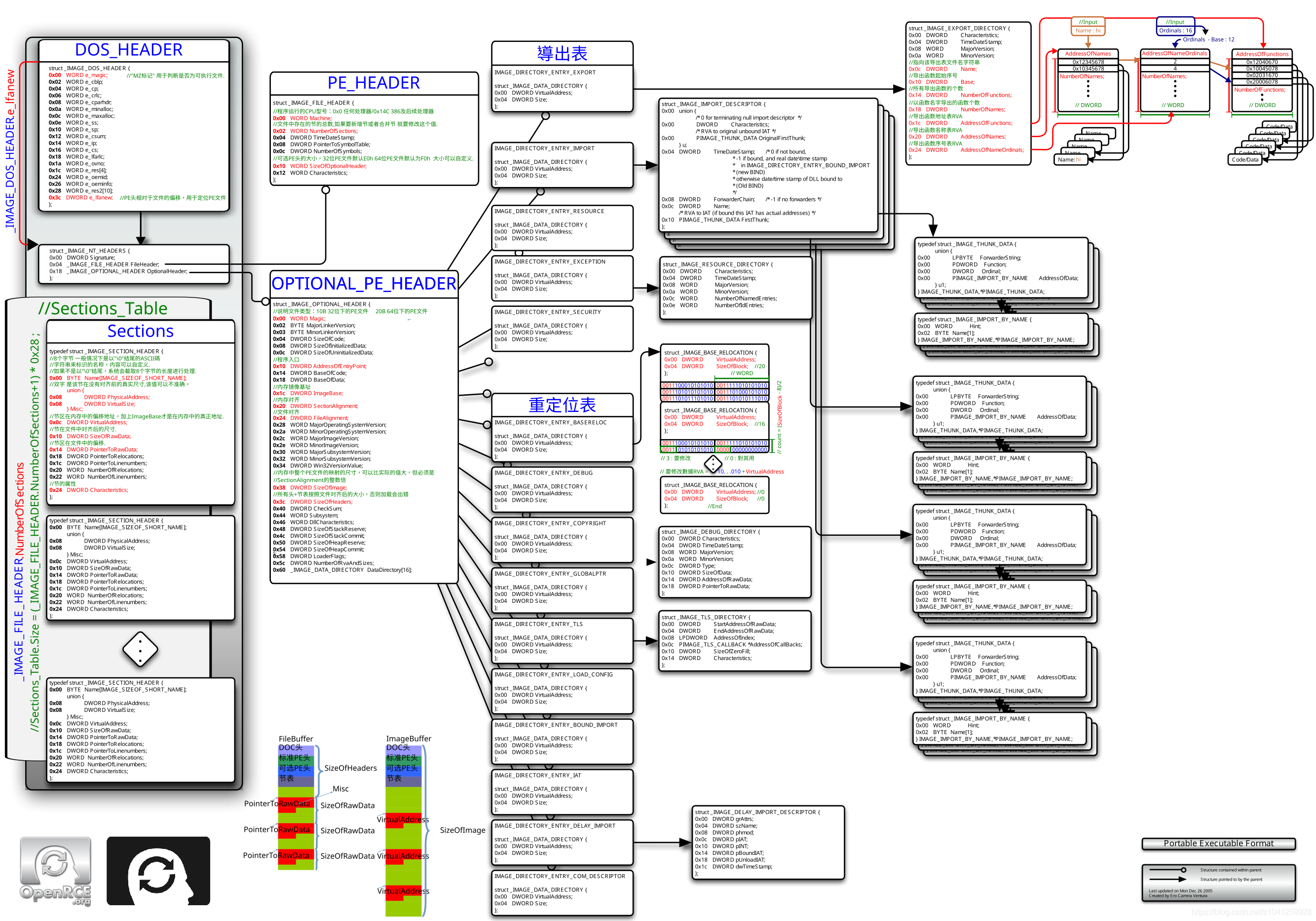
相对重要的概念
| 名称 | 描述 |
|---|---|
| 地址 | 是“虚拟地址”而不是“物理地址”。为什么不是“物理地址”呢?因为数据在内存的位置经常在变,这样可以节省内存开支、避开错误的内存位置等的优势。同时用户并不需要知道具体的“真实地址”,因为系统自己会为程序准备好内存空间的(只要内存足够大) |
| 镜像文件 | 包含以EXE文件为代表的“可执行文件”、以DLL文件为代表的“动态链接库”。镜像(直接“复制”到内存,有“镜像”的某种意思),就是指pe文件经过拉伸后在内存中的整个文件 |
| RVA | Relatively Virtual Address。偏移(又称“相对虚拟地址”)。相对镜像基址的偏移。 |
| 节 | 节是PE文件中代码或数据的基本单元。原则上讲,节只分为“代码节”和“数据节”。 |
| VA | Virtual Address PE文件中的指令被装入内存后的地址VA(虚拟地址)=IB(基址)+RVA(偏移) |
| 装载地址 | 也叫基地址,Image Base PE装入内存时的基地址,默认情况下,EXE文件在内存中的基地址是0x00400000,DLL文件是0x10000000. 由编译器决定 |
| 文件偏移 | FileOffset、RAWOffset 即文件存储在磁盘(而非内存)时的相对文件头(0位置)的位置,起始值就是0。用winhex打开一个pe文件,看到的就是文件偏移 |
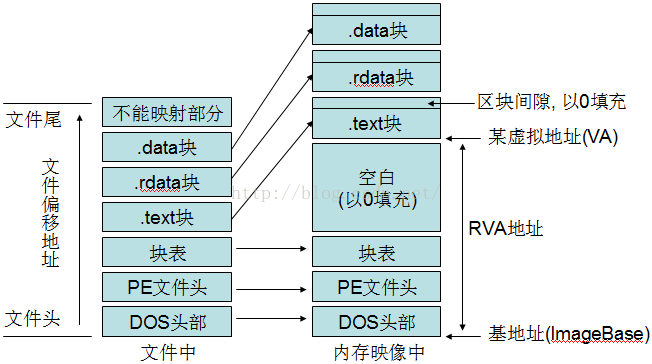
32bit和64bit的PE文件格式大同小异,64bit的只不过修改了PE格式的少数几个域,大部分情况下,操作PE的代码可以同时适用32bit和64bit
EXE和DLL都是PE格式文件 只不过其中的标识位不一样
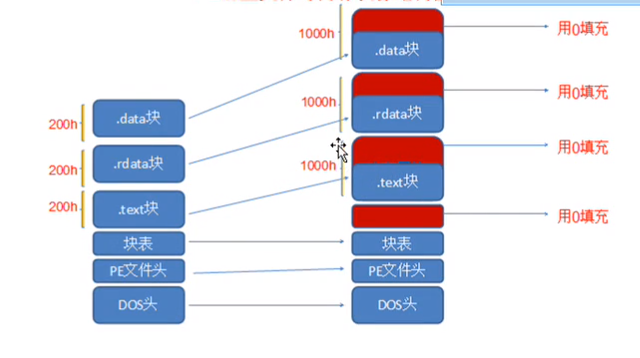
内存对齐:
x86对齐:
硬盘对齐 每200h个字节进行对齐
内存对齐 每1000h个字节进行对齐
PE文件组成
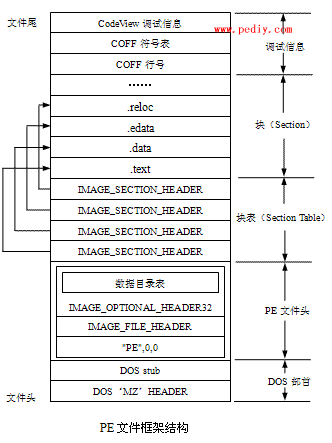
主要是4部分:DOS、PE文件头、节表、节数据(文末有详细的对应表,比C更直观)
DOS
DOS内一共两部分,一个是DOS头,另一个是DOS Stub。
DOS头:(历史遗留)
dos头一共64字节
重要的数据:
1 | WORD e_magic //“MZ标记”用于判断是否为可执行文件 |
完整的结构:
1 | //注释掉的不需要重点分析 |
DOS Stub:
大小不恒定,但是可以通过PE头的位置计算出来;而且病毒程序可以在这里注入代码
PE文件头
PE头一共可分3部分:标志部分,标准PE头、可选PE头
标志部分:
四个字节,内容是PE00
标准PE头:
大小是20个字节
重要的数据:
1 | WORD Machine; //※程序执行的CPU平台:0X0:任何平台,0X14C:intel i386及后续处理器 |
完整的结构:
1 | //标准PE头:最基础的文件信息,共20字节 |
可选PE头:
32bitPE文件的大小是224字节,这个结构题大小可以扩展,在标准PE头中修改可选PE头的大小
重要的数据:
1 | WORD Magic; //说明文件类型 10B为32位下的PE文件 20B为64位下的PE文件 |
完整的结构:
1 | //可选PE头 |
节表
节表占40个字节,节表是用来确定节数据的属性的,数据都存在节中
重要的数据成员:
1 | Misc.(DWORD) VirtualSize; //节的尺寸 |
| 位置 | 描述 |
|---|---|
| 1 | 已经废除 |
| 2 | |
| 3 | |
| 4 | |
| 5 | |
| 6 | 此节包含可执行代码。代码段才用“.text” |
| 7 | 此节包含已初始化的数据。“.data” |
| 8 | 此节包含未初始化的数据。“.bss” |
| 9 | 已经废除 |
| 10 | |
| 11 | |
| 12 | |
| 13 | |
| 14 | |
| 15 | |
| 16 | 此节包含通过全局指针(GP)来引用的数据。 |
| 17 | 已经废除 |
| 18 | |
| 19 | |
| 20 | |
| 21 | |
| 22 | |
| 23 | |
| 24 | |
| 25 | 此节包含扩展的重定位信息。 |
| 26 | 此节可以在需要时被丢弃。 |
| 27 | 此节不能被缓存。 |
| 28 | 此节不能被交换到页面文件中。 |
| 29 | 此节可以在内存中共享。 |
| 30 | 此节可以作为代码执行。 |
| 31 | 此节可读。(几乎都设置此节) |
| 32 | 此节可写。 |
完整的节表结构:
1 | typedef struct _IMAGE_SECTION_HEADER { |
节数据(转载)
下表描述了保留的节以及它们的属性,后面是对出现在可执行文件中的节的详细描述。这些节是微软的编译产品所定义的不是系统定义的,实际可以不拘泥于此。
| 节名 | 内容 |
|---|---|
| .bss | 未初始化的数据 |
| .data | 代码节 |
| .edata | 导出表 |
| .idata | 导入表 |
| .idlsym | 包含已注册的SEH,它们用以支持IDL属性 |
| .pdata | 异常信息 |
| .rdata | 只读的已初始化数据(用于常量) |
| .reloc | 重定位信息 |
| .rsrc | 资源目录 |
| .sbss | 与GP相关的未初始化数据 |
| .sdata | 与GP相关的已初始化数据 |
| .srdata | 与GP相关的只读数据 |
| .text | 默认代码节 |
.edata节:
文件A的函数K被文件B调用时,函数K就称为导出函数。导出函数通常出现在DLL中,也可以是exe文件。
下表描述了导出节的一般结构。
| 表名 | 描述 |
|---|---|
| 导出目录表 | 它给出了其它各种导出表的位置和大小。 |
| 导出地址表 | 一个由导出函数的RVA组成的数组。它们是导出的函数和数据在代码节和数据节内的实际地址。其它镜像文件可以通过使用这个表的索引(序数)来调用函数。 |
| 导出名称指针表 | 一个由指向导出函数名称的指针组成的数组,按升序排列。大小写敏感。 |
| 导出序数表 | 一个由对应于导出名称指针表中各个成员的序数组成的数组。它们的对应是通过位置来体现的,因此导出名称指针表与导出序数表成员数目必须相同。 |
| 导出名称表 | 一系列以NULL结尾的ASCII码字符串。导出名称指针表中的成员都指向这个区域。它们都是公用名称,函数导入与导出就是通过它们。 |
当其它镜像文件通过名称导入函数时,Win32加载器通过导出名称指针表来搜索匹配的字符串。如果找到,它就查找导出序数表中相应的成员(也就是说,将找到的导出名称指针表的索引作为导出序数表的索引来使用)来获取与导入函数相关联的序数。获取的这个序数是导出地址表的索引,这个索引对应的元素给出了所需函数的实际位置。每个导出函数都可以通过序数进行访问。
当其它镜像文件通过序数导入函数时,就不再需要通过导出名称指针表来搜索匹配的字符串。因此直接使用序数效率会更高。但是导出名称容易记忆,它不需要用户记住各个符号在表中的索引。
导出目录表
导出目录表是导出函数信息的开始部分,它描述了导出函数信息中其余部分的内容。
| 偏移 | 大小 | 英文名 | 描述 |
|---|---|---|---|
| 0 | 4 | Export Flags | 保留,必须为0。 |
| 4 | 4 | Time/Date StampMajor Version | 导出函数被创建的日期和时间。这个值与NT头的第一部分TimeDateStamp相同。 |
| 8 | 2 | Major Version | 主版本号。 |
| 10 | 2 | Minor Version | 次版本号。 |
| 12 | 4 | Name RVA | 包含这个DLL全名的ASCII码字符串RVA。以一个NULL字节结尾。 |
| 16 | 4 | Ordinal Base | 导出函数的起始序数值。它通常被设置为1。 |
| 20 | 4 | NumberOfFunctions | 导出函数中所有元素的数目。 |
| 24 | 4 | NumberOfNames | 导出名称指针表中元素的数目。它同时也是导出序数表中元素的数目。 |
| 28 | 4 | AddressOfFunctions | 导出地址表RVA。 |
| 32 | 4 | AddressOfNames | 导出名称指针表RVA。 |
| 36 | 4 | AddressOfNameOrdinals | 导出序数表RVA。 |
导出地址表(Export Address Table,EAT)
导出地址表的格式为下表所述的两种格式之一。如果指定的地址不是位于导出节(其地址和长度由NT头给出)中,那么这个域就是一个Export RVA;否则这个域是一个Forwarder RVA,它给出了一个位于其它DLL中的符号的名称。
| 偏移 | 大小 | 域 | 描述 |
|---|---|---|---|
| 0 | 4 | Export RVA | 当加载进内存时,导出函数RVA。 |
| 0 | 4 | Forwarder RVA | 这是指向导出节中一个以NULL结尾的ASCII码字符串的指针。这个字符串必须位于Export Table(导出表)数据目录项给出的范围之内。这个字符串给出了导出函数所在DLL的名称以及导出函数的名称(例如“MYDLL.expfunc”),或者DLL的名称以及导出函数的序数值(例如“MYDLL.#27”)。 |
Forwarder RVA导出了其它镜像中定义的函数,使它看起来好像是当前镜像导出的一样。因此对于当前镜像来说,这个符号同时既是导入函数又是导出函数。
例如对于Windows XP系统中的Kernel32.dll文件来说,它导出的“HeapAlloc”被转发到“NTDLL.RtlAllocateHeap”。这样就允许应用程序使用Windows XP系统中的Ntdll.dll模块而不需要实际包含任何相关的导入信息。应用程序的导入表只与Kernel32.dll有关。
导出地址表的的值有时为0,此时表明这里没有导出函数。这是为了能与以前版本兼容,省去修改的麻烦。
导出名称指针表
导出名称指针表是由导出名称表中的字符串的地址(RVA)组成的数组。二进制进行排序的,以便于搜索。
只有当导出名称指针表中包含指向某个导出名称的指针时,这个导出名称才算被定义。换句话说,导出名称指针表的值有可能为0,这是为了能与前面版本兼容。
导出序数表
导出序数表是由导出地址表的索引组成的一个数组,每个序数长16位。必须从序数值中减去Ordinal Base域的值得到的才是导出地址表真正的索引。注意,导出地址表真正的索引真正的索引是从0开始的。由此可见,微软弄出Ordinal Base是找麻烦的。导出序数表的值和导出地址表的索引的值都是无符号数。
导出名称指针表和导出名称序数表是两个并列的数组,将它们分开是为了使它们可以分别按照各自的边界(前者是4个字节,后者是2个字节)对齐。在进行操作时,由导出名称指针这一列给出导出函数的名称,而由导出序数这一列给出这个导出函数对应的序数。导出名称指针表的成员和导出序数表的成员通过同一个索引相关联。
导出名称表(Export Name Table,ENT)
导出名称表的结构就是长度可变的一系列以NULL结尾的ASCII码字符串。 导出名称表包含的是导出名称指针表实际指向的字符串。这个表的RVA是由导出名称指针表的第1个值来确定的。这个表中的字符串都是函数名称,其它文件可以通过它们调用函。
举例
①用序数调用
当可执行文件用序数调用函数时,该序数就是导出函数地址表的真实索引。如果索引是错误的就有可能出现不可预知的错误。最著名的例子就是Windows XP在升级Server 2补丁之后,有很多程序都不能运行就是这个原因。微软用序数这种方法被大多数危险程序(病毒、木马)所引用,同样的微软自己也用这种方法来使用一些隐含的函数。最后受害者还是广大的用户,因为使用序数方法的绝大部分程序是有着不可告人的目的的。
②用函数名调用
当可执行文件用函数名调用时,加载器会通过AddressOfNames以2进制的方法找到第一个相同的函数名。假如找到的是第X个函数名,则在AddressOfNameOrdinals中取出第X个值,该值再减去Ordinal Base则为函数地址的真实索引。
idata节
首先,您得了解什么是导入函数。一个导入函数是被某模块调用的但又不在调用者模块中的函数,因而命名为“import(导入)”。导入函数实际位于一个或者更多的DLL里。调用者模块里只保留一些函数信息,包括函数名及其驻留的DLL名。现在,我们怎样才能找到PE文件中保存的信息呢? 转到 data directory 寻求答案吧。
文件中导入信息的典型布局如下:

典型的导入节布局
导入目录表
导入目录表是由导入目录项组成的数组,每个导入目录项对应着一个导入的DLL。最后一个导入目录项是空的(全部域的值都为NULL),用来指明目录表的结尾。
每个导入目录项的格式如下:
| 偏移 | 大小 | 域 | 描述 |
|---|---|---|---|
| 0 | 4 | Import Lookup Table RVA | 导入查找表的RVA。这个表包含了每一个导入函数的名称或序数。 |
| 4 | 4 | Time/Date Stamp | 当镜像与相应的DLL绑定之后,这个域被设置为这个DLL的日期/时间戳。 |
| 8 | 4 | Forwarder Chain | 第一个转发项的索引。 |
| 12 | 4 | Name RVA | 包含DLL名称的ASCII码字符串RVA。 |
| 16 | 4 | Import Address RVA | 导入地址表的RVA。这个表的内容与导入查找表的内容完全一样。 |
导入查找表
导入查找表是由长度为32位(PE32)或64位(PE32+)的数字组成的数组。其中的每一个元素都是位域,其格式如下表所示。在这种格式中,位31(PE32)或位63(PE32+)是最高位。这些项描述了从给定的DLL导入的所有函数。最后一个项被设置为0(NULL),用来指明表的结尾。
| 偏移 | 大小 | 位域 | 描述 |
|---|---|---|---|
| 31/63 | 1 | Ordinal/Name Flag | 如果这个位为1,说明是通过序数导入的。否则是通过名称导入的。测试这个位的掩码为0x80000000(PE32)或)0x8000000000000000(PE32+)。 |
| 15-0 | 16 | Ordinal Number | 序数值(16位长)。只有当Ordinal/Name Flag域为1(即通过序数导入)时才使用这个域。位30-15(PE32)或62-15(PE32+)必须为0。 |
| 30-0 | 31 | Hint/Name Table RVA | 提示/名称表项的RVA(31位长)。只有当Ordinal/Name Flag域为0(即通过名称导入)时才使用这个域。对于PE32+来说,位62-31必须为0。 |
提示/名称表
提示/名称表中的每一个元素结构如下:
| 偏移 | 大小 | 域 | 描述 |
|---|---|---|---|
| 0 | 2 | Hint | 指出名称指针表的索引。当搜索匹配字符串时首选使用这个值。如果匹配失败,再在DLL的导出名称指针表中进行2进制搜索。 |
| 2 | 可变 | Name | 包含导入函数名称的ASCII码字符串。这个字符串必须与DLL导出的函数名称匹配。同时这个字符串区分大小写并且以NULL结尾。 |
| * | 0或1 | Pad | 为了让提示/名称表的下一个元素出现在偶数地址,这里可能需要填充0个或1个NULL字节。 |
导入地址表
导入地址表的结构和内容与导入查找表完全一样,直到文件被绑定。在绑定过程中,用导入函数的32位(PE32)或64位(PE32+)地址覆盖导入地址表中的相应项。这些地址是导入函数的实际内存地址,尽管技术上仍把它们称为“虚拟地址”。加载器通常会处理绑定。
.reloc节
基址重定位表包含了镜像中所有需要重定位的内容。NT头中的数据目录中的Base Relocation Table(基址重定位表)域给出了基址重定位表所占的字节数。基址重定位表被划分成许多块,每一块表示一个4K页面范围内的基址重定位信息,它必须从32位边界开始。
基址重定位块
每个基址重定位块的开头都是如下结构:
| 偏移 | 大小 | 域 | 描述 |
|---|---|---|---|
| 0 | 4 | Page RVA | 将镜像基址与这个域(页面RVA)的和加到每个偏移地址处最终形成一个VA,这个VA就是要进行基址重定位的地方。 |
| 4 | 4 | Block Size | 基址重定位块所占的总字节数,其中包括Page RVA域和Block Size域以及跟在它们后面的Type/Offset域。 |
Block Size域后面跟着数目不定的Type/Offset位域。它们中的每一个都是一个WORD(2字节),其结构如下:
| 偏移 | 大小 | 域 | 描述 |
|---|---|---|---|
| 0 | 4位 | Type | 它占这个WORD的最高4位,这个值指出需要应用的基址重定位类型。参考5.4.2节“基址重定位类型”。 |
| 0 | 12位 | Offset | 它占这个WORD的其余12位,这个值是从基址重定位块的Page RVA域指定的地址处开始的偏移。这个偏移指出需要进行基址重定位的位置。 |
为了进行基址重定位,需要计算镜像的首选基地址与实际被加载到的基地址之差。如果镜像本身就被加载到了其首选基地址,那么这个差为零,因此也就不需要进行基址重定位了。
基址重定位类型
| 值 | 描述 |
|---|---|
| 0 | 基址重定位被忽略。这种类型可以用来对其它块进行填充。 |
| 1 | 基址重定位时将差值的高16位加到指定偏移处的一个16位域上。这个16位域是一个32位字的高半部分。 |
| 2 | 基址重定位时将差值的低16位加到指定偏移处的一个16位域上。这个16位域是一个32位字的低半部分。 |
| 3 | 基址重定位时将所有的32位差值加到指定偏移处的一个32位域上。 |
| 4 | 进行基址重定位时将差值的高16位加到指定偏移处的一个16位域上。这个16位域是一个32位字的高半部分,而这个32位字的低半部分被存储在紧跟在这个Type/Offset位域后面的一个16位字中。也就是说,这一个基址重定位项占了两个Type/Offset位域的位置。 |
| 5 | 对MIPS平台的跳转指令进行基址重定位。 |
| 6 | 保留,必须为0 |
| 7 | 保留,必须为0 |
| 9 | 对MIPS16平台的跳转指令进行基址重定位。 |
| 10 | 进行基址重定位时将差值加到指定偏移处的一。 |
一些注意信息
1.PE头是怎么计算的?
SizeOfHeaders所指的头是从文件的第1个字节开始算起的,而不是从PE标记开始算起的。快速的计算方法是从文件的偏移0x3C(第59字节)处获得一个4字节的PE文件签名的偏移地址,这个偏移地址就是本文所定义的DOS头的大小。NT头在32位系统是244字节,在64位系统是260字节。节头的大小由NT头的第1部分的NumberOfSections(节的数量)*40字节(每个节头是40字节)得出。如此,DOS头、NT头、节头3个头的大小加起来并向上舍入为FileAlignment(文件对齐)的正整数倍的最小值就是SizeOfHeaders(头大小)值。
2.节数量的问题
Windows读取NumberOfSections的值然后检查节表里的每个结构,如果找到一个全0结构就结束搜索,否则一直处理完NumberOfSections指定数目的结构。没有规定节头必须以全0结构结束。所以加载器使用了双重标准——全0、达到NumberOfSections数量就不再搜索了。
3.未初始化问题
①未初始化数据在文件中是不占空间的,但在内存里还是会占空间的,它们依然依据指定的大小存在内存里。所以说未初始化数据只在文件大小上有优势,在内存里与已初始化数据是一样的。
②未初始化数据的方法有2种:1是通过节头的VirtualSize>SizeOfRawData。未初始化数据的大小就是VirtualSize-SizeOfRawData的值。2是节特征的标志置为“此节包含未初始化的数据”,这时SizeOfUninitializedData才会非0。现在 都使用第1种,把它们集成到.data里面可以加快速度。
4.已初始化问题
数据目录里面所对应的块中除了属性证书表、调试信息和几个废除的目录项外,全都属于SizeOfInitializedData(已初始化数据大小)范围。当然,已初始化数据不只这些,还可以是常见的代码段等等。
5.节对齐的问题
如果NT头的SectionAlignment域的值小于相应操作系统(有些资料说是根据CPU来的,这不一定。因为CPU本身就允许改分页大小,只是大部分时候操作系统是用CPU默认值的。x86平台默认页面大小是4K。IA-64平台默认页面大小是8K。MIPS平台默认页面大小是4K。Itanium平台默认页面大小是8K。)平台的页面大小,那么镜像文件有一些附加的限制。对于这种文件,当镜像被加载到内存中时,节中数据在文件中的位置必须与它在内存中的位置相等,因此节中数据的物理偏移与RVA相同。
6.镜像大小
SizeOfImage所代表的内存镜像大小没有包含属性证书表和调试信息,这是因为加载器并不将属性证书和调试信息映射进内存。同时加载器规定,属性证书和调试信息必须被放在镜像文件的最后,并且属性证书表在调试信息节之前。
7.数据的组织
CPU的段主要分为4个:代码段、数据段、堆栈段、附加段。而操作系统给程序员留下只有代码段和数据段,堆栈段和附加段就由系统自行处理了,我们不用管。PE文件的数据组织方式是以BaseOfCode、BaseOfData为基准,以节为主体,以数据目录为辅助。
①BaseOfCode、BaseOfData是与后面相应的代码节、数据节的VirtualAddress一致。(这里的数据节是狭义的数据节,是特指代码段、数据目录所指定的数据除外的那一部分,也就是我们编程时定义的常量、变量、未初始化数据等)
②所有的代码、数据都必须在节里面,否则就算是代码基址、数据基址、数据目录都有指定,而节头里没有指定,加载器也会报错,不能运行
③导入函数、导出函数、资源、重定位表等是为了辅助程序主体的,这些都由系统负责处理
对应表
NT头(244或260个字节)
紧跟着PE文件签名之后,是NT头。NT头分成3个部分,第一个部分就是PE标准头,后两个部分统称PE可选头。
因为第2部分在32与64位系统里有区别,第3部分虽然也是头,但实际很不像“头”。
第1部分(20个字节)
| 偏移 | 大小 | 英文名 | 中文名 | 描述 |
|---|---|---|---|---|
| 0 | 2 | Machine | 机器数 | 标识CPU的数字。参考3.2.1节“机器类型”。 |
| 2 | 2 | NumberOfSections | 节数 | 节的数目。Windows加载器限制节的最大数目为96。 |
| 4 | 4 | TimeDateStamp | 时间/日期标记 | UTC时间1970年1月1日00:00起的总秒数的低32位,它指出文件何时被创建。 |
| 8 | 8 | 已经废除 | ||
| 16 | 2 | SizeOfOptionalHeader | 可选头大小 | 第2部分+第3部分的总大小。这个大小在32位和64位文件中是不同的。对于32位文件来说,它是224;对于64位文件来说,它是240。 |
| 18 | 2 | FillCharacteristics | 文件特征值 | 指示文件属性的标志。参考3.2.2节“特征”。 |
第2部分(96或112个字节)
| 偏移 | 大小 | 英文名 | 中文名 | 描述 |
|---|---|---|---|---|
| 0 | 2 | Magic | 魔数 | 这个无符号整数指出了镜像文件的状态。 0x10B表明这是一个32位镜像文件。 0x107表明这是一个ROM镜像。 0x20B表明这是一个64位镜像文件。 |
| 2 | 1 | MajorLinkerVersion | 链接器的主版本号 | 链接器的主版本号。 |
| 3 | 1 | MinorLinkerVersion | 链接器的次版本号 | 链接器的次版本号。 |
| 4 | 4 | SizeOfCode | 代码节大小 | 一般放在“.text”节里。如果有多个代码节的话,它是所有代码节的和。必须是FileAlignment的整数倍,是在文件里的大小。 |
| 8 | 4 | SizeOfInitializedData | 已初始化数大小 | 一般放在“.data”节里。如果有多个这样的节话,它是所有这些节的和。必须是FileAlignment的整数倍,是在文件里的大小。 |
| 12 | 4 | SizeOfUninitializedData | 未初始化数大小 | 一般放在“.bss”节里。如果有多个这样的节话,它是所有这些节的和。必须是FileAlignment的整数倍,是在文件里的大小。 |
| 16 | 4 | AddressOfEntryPoint | 入口点 | 当可执行文件被加载进内存时其入口点RVA。对于一般程序镜像来说,它就是启动地址。为0则从ImageBase开始执行。对于dll文件是可选的。 |
| 20 | 4 | BaseOfCode | 代码基址 | 当镜像被加载进内存时代码节的开头RVA。必须是SectionAlignment的整数倍。 |
| 24 | 4 | BaseOfData | 数据基址 | 当镜像被加载进内存时数据节的开头RVA。(在64位文件中此处被并入紧随其后的ImageBase中。)必须是SectionAlignment的整数倍。 |
| 28/24 | 4/8 | ImageBase | 镜像基址 | 当加载进内存时镜像的第1个字节的首选地址。它必须是64K的倍数。DLL默认是10000000H。Windows CE 的EXE默认是00010000H。Windows 系列的EXE默认是00400000H。 |
| 32 | 4 | SectionAlignment | 内存对齐 | 当加载进内存时节的对齐值(以字节计)。它必须≥FileAlignment。默认是相应系统的页面大小。 |
| 36 | 4 | FileAlignment | 文件对齐 | 用来对齐镜像文件的节中的原始数据的对齐因子(以字节计)。它应该是界于512和64K之间的2的幂(包括这两个边界值)。默认是512。如果SectionAlignment小于相应系统的页面大小,那么FileAlignment必须与SectionAlignment相等。 |
| 40 | 2 | MajorOperatingSystemVersion | 主系统的主版本号 | 操作系统的版本号可以从“我的电脑”→“帮助”里面看到,Windows XP是5.1。5是主版本号,1是次版本号 |
| 42 | 2 | MinorOperatingSystemVersion | 主系统的次版本号 | |
| 44 | 2 | MajorImageVersion | 镜像的主版本号 | |
| 46 | 2 | MinorImageVersion | 镜像的次版本号 | |
| 48 | 2 | MajorSubsystemVersion | 子系统的主版本号 | |
| 50 | 2 | MinorSubsystemVersion | 子系统的次版本号 | |
| 52 | 2 | Win32VersionValue | 保留,必须为0 | |
| 56 | 4 | SizeOfImage | 镜像大小 | 当镜像被加载进内存时的大小,包括所有的文件头。向上舍入为SectionAlignment的倍数。 |
| 60 | 4 | SizeOfHeaders | 头大小 | 所有头的总大小,向上舍入为FileAlignment的倍数。可以以此值作为PE文件第一节的文件偏移量。 |
| 64 | 4 | CheckSum | 校验和 | 镜像文件的校验和。计算校验和的算法被合并到了Imagehlp.DLL 中。以下程序在加载时被校验以确定其是否合法:所有的驱动程序、任何在引导时被加载的DLL以及加载进关键Windows进程中的DLL。 |
| 68 | 2 | Subsystem | 子系统类型 | 运行此镜像所需的子系统。参考后面的“Windows子系统”部分。 |
| 70 | 2 | DllCharacteristics | DLL标识 | 参考后面的“DLL特征”部分。 |
| 72 | 4/8 | SizeOfStackReserve | 堆栈保留大小 | 最大栈大小。CPU的堆栈。默认是1MB。 |
| 76/80 | 4/8 | SizeOfStackCommit | 堆栈提交大小 | 初始提交的堆栈大小。默认是4KB。 |
| 80/88 | 4/8 | SizeOfHeapReserve | 堆保留大小 | 最大堆大小。编译器分配的。默认是1MB。 |
| 84/96 | 4/8 | SizeOfHeapCommit | 堆栈交大小 | 初始提交的局部堆空间大小。默认是4KB。 |
| 88/104 | 4 | LoaderFlags | 保留,必须为0 | |
| 92/108 | 4 | NumberOfRvaAndSizes | 目录项数目 | 数据目录项的个数。由于以前发行的Windows NT的原因,它只能为16。 |
第3部分数据目录(128个字节)
| 偏移 (PE32/PE32+) | 大小 | 英文名 | 描述 |
|---|---|---|---|
| 96/112 | 8 | Export Table | 导出表的地址和大小。参考5.1节“.edata” |
| 104/120 | 8 | Import Table | 导入目录表的地址和大小。参考5.2.1节“.idata” |
| 112/128 | 8 | Resource Table | 资源表的地址和大小。参考5.6节“.rsrc” |
| 120/136 | 8 | Exception Table | 异常表的地址和大小。参考5.3节“.pdata” |
| 128/144 | 8 | Certificate Table | 属性证书表的地址和大小。参考6节“属性证书表” |
| 136/152 | 8 | Base Relocation Table | 基址重定位表的地址和大小。参考5.4节“.reloc” |
| 144/160 | 8 | Debug | 调试数据起始地址和大小。 |
| 152/168 | 8 | Architecture | 保留,必须为0 |
| 160/176 | 8 | Global Ptr | 将被存储在全局指针寄存器中的一个值的RVA。这个结构的Size域必须为0 |
| 168/184 | 8 | TLS Table | 线程局部存储(TLS)表的地址和大小。 |
| 176/192 | 8 | Load Config Table | 加载配置表的地址和大小。参考5.5节“加载配置结构” |
| 184/200 | 8 | Bound Import | 绑定导入查找表的地址和大小。参考5.2.2节“导入查找表” |
| 192/208 | 8 | IAT | 导入地址表的地址和大小。参考5.2.4节“导入地址表” |
| 200/216 | 8 | Delay Import Descriptor | 延迟导入描述符的地址和大小。 |
| 208/224 | 8 | CLR Runtime Header | CLR运行时头部的地址和大小。(已废除) |
| 216/232 | 8 | 保留,必须为0 |
引用来源:
https://blog.csdn.net/cs2626242/article/details/79391599
https://blog.csdn.net/jznsmail/article/details/293358
https://blog.csdn.net/qq_28526211/article/details/88836043