PE文件结构详见上一篇博客:
概要
总共可以分为八个步骤:
1.将PE文件用ReadFile读取数据
2.根据PE结构获取镜像大小,在自己的程序中申请可读可写可执行的内存
3.将申请的空间全部填为0
4.将用ReadFile读取的数据映射到内存中
5.修复重定位
6.根据PE结构的导入表,加载所需要的dll,并获取导入函数的地址并写入导入表中。
7.修改PE文件的加载基址
8.跳转到PE的入口点处执行
数据目录
用途:
用来找到编译器加到PE文件中的信息,这些信息包含了如:
- PE程序的图标信息
- 用了哪些系统提供的函数(导入的函数)
- 为其他程序提供了哪些函数(导出的函数)
定位:
可选PE头的最后一个成员,就是数据目录,一共16个:
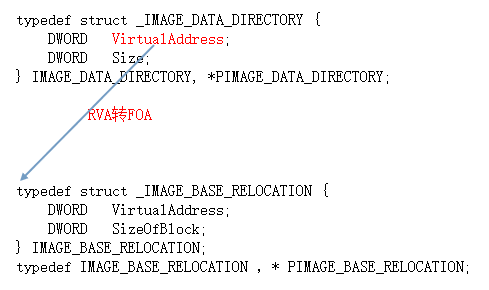
1 | typedef struct _IMAGE_DATA_DIRECTORY { |
分别是:导出表、导入表、资源表、异常信息表、安全证书表、重定位表、调试信息表、版权所以表、全局指针表、TLS表、加载配置表、绑定导入表、IAT表、延迟导入表、COM信息表 最后一个保留未使用。
和程序执行有关的:
和程序运行时息息相关的表有:
导出表
导入表
重定位表
IAT表
导出表
定位导出表
数据目录项里的第一个结构就是导出表。
1 | typedef struct _IMAGE_DATA_DIRECTORY { |
VirtualAddress 导出表的RVA
Size 导出表大小
导出表结构
数据目录里的只是导出表在哪里的信息,并不包含导出表真正的信息
如何在FileBuffer中找到这个结构呢?在VirtualAddress中存储的是RVA,想在FileBuffer中定位,则需要先转换成FOA
真正的导出表结构:
1 | typedef struct _IMAGE_EXPORT_DIRECTORY { |
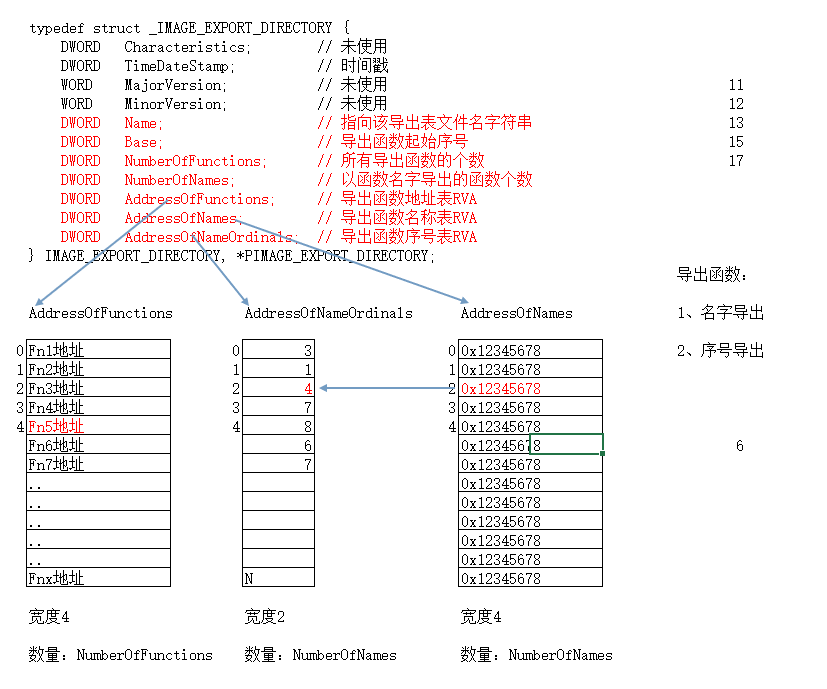
AddressOfFunctions说明:
该表中元素宽度为4个字节
该表中存储所有导出函数的地址
该表中个数由NumberOfFunctions决定
该表项中的值是RVA, 加上ImageBase才是函数真正的地址
定位:
IMAGE_EXPORT_DIRECTORY->AddressOfFunctions 中存储的是该表的RVA 需要先转换成FOA
AddressOfNames说明:
该表中元素宽度为4个字节
该表中存储所有以名字导出函数的名字的RVA
该表项中的值是RVA, 指向函数真正的名称
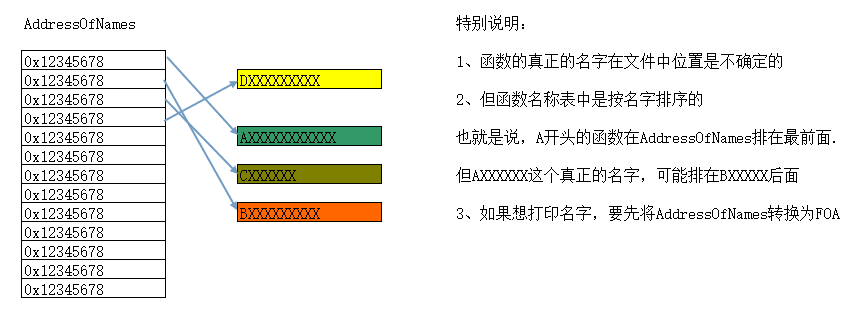
AddressOfNameOrdinals

导出表总结:
为什么要分成3张表?
1、函数导出的个数与函数名的个数未必一样.所以要将函数地址表和函数名称表分开.
2、函数地址表是不是一定大于函数名称表?
未必,一个相同的函数地址,可能有多个不同的名字.
3、如何根据函数的名字获取一个函数的地址?
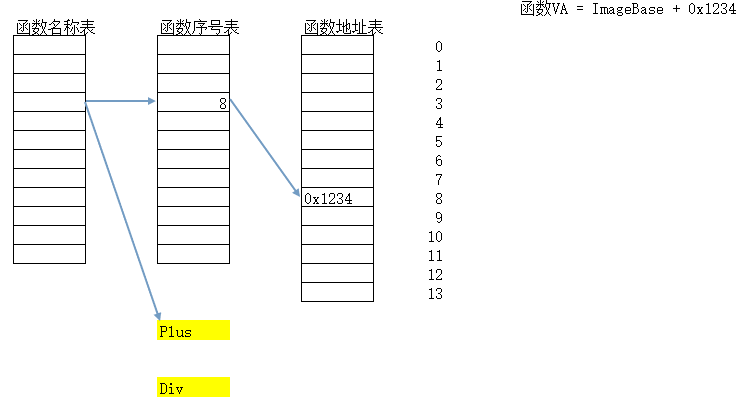
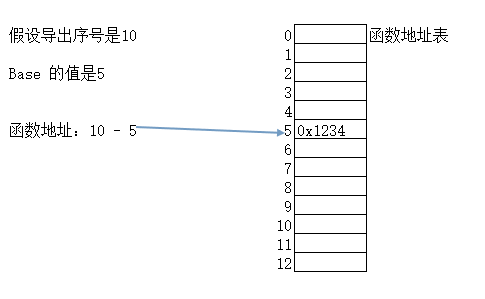
4、如何根据函数的导出序号获取一个函数的地址?
程序加载的过程

1、一般情况下,EXE都是可以按照ImageBase的地址进行加载的。因为EXE拥有自己独立的4GB虚拟内存空间,但是DLL不是,有EXE使用它时,DLL才加载到相关EXE的进程空间
2、为了提高搜索的速度,模块间地址也是要对齐的,模块地址对齐为10000H,也就是64K
引出重定位表:

1、也就是说,如果程序能够按照预定的ImageBase来加载的话,那么就不需要重定位表
这也是为什么exe很少有重定位表,而DLL大多都有重定位表的原因。一旦位置冲突,由于编译过程中编译器把值已经写死了(写的不是偏移地址,写的是偏移加基址(编译器默认认为不会发生位置冲突)),很有可能导致程序出错
2、一旦某个模块没有按照ImageBase进行加载,那么所有类似上面中的地址就都需要修正,否则,引用的地址就是无效的.
3、一个EXE中,需要修正的地方会很多,那我们如何来记录都有哪些地方需要修正呢?
答案就是重定位表
重定位表
定位:
数据目录项的第6个结构,就是重定位表
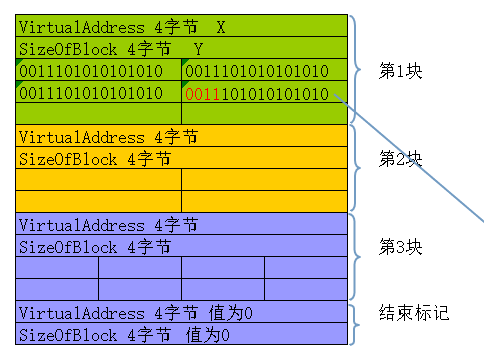
在内存中的形式类似这样,按块划分
说明:
1、通过IMAGE_DATA_DIRECTORY结构的VirtualAddress
属性 找到第一个IMAGE_BASE_RELOCATION
2、判断一共有几块数据:
最后一个结构的标记是VirtualAddress与SizeOfBlock都为0
3、具体项 宽度:2字节
也就是这个数据
内存中的页大小是1000H 也就是说2的12次方 就可以表示
一个页内所有的偏移地址 具体项的宽度是16字节 高四位
代表类型:值为3 代表的是需要修改的数据 值为0代表的是
用于数据对齐的数据,可以不用修改.也就是说 我们只关注
高4位的值为3的就可以了.
4、VirtualAddress 宽度:4字节
当前这一个块的数据,每一个低12位的值+VirtualAddress 才是
真正需要修复的数据的RVA
真正的RVA = VirtualAddress + 具体项的低12位
5、SizeOfBlock 宽度:4字节
当前块的总大小
只有知道块的总大小才能索引到下一个块,因为没有其他数据来记录下一个块的地址
具体项的数量 = (SizeOfBlock - 8)/2
6、分块的目的是为了节省空间开销,如果每次都存完整的地址,那么32bit的系统每个地址都需要4B,则远远不够用,所以对高位相同的地址进行这样的简化处理。
分块是以地址块为单位(一整块的地址用一块重定位表来表示)

回过头来看重定位表的作用:
重定位表只是为了让自己这个DLL程序里的地址在运行时是正确的
所以PE文件中的重定位表是为了自身程序(EXE、DLL)在被其他程序加载时,没有被正常加载到预期位置,但为了让主程序正常调用,而给系统的一种指导(就是告诉系统,如果我被加载到的位置和我预计的位置不一样,那么就要按照我给出的重定位表进行修改)
注:如果一个程序不会被别的程序加载,那么这个程序的重定位表是用不上的,因为除了内核重载的情况,主程序的2G虚拟内存空间不会被占用。
导入表
定位:
数据目录项的第2个结构存储了导入表的信息
导入表的结构:
1 | typedef struct _IMAGE_IMPORT_DESCRIPTOR { |
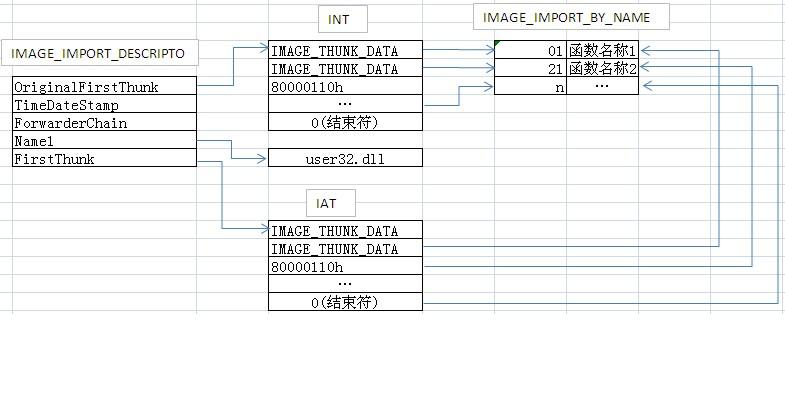
PE文件加载前(这张图也可以更形象的认识导入表的结构):
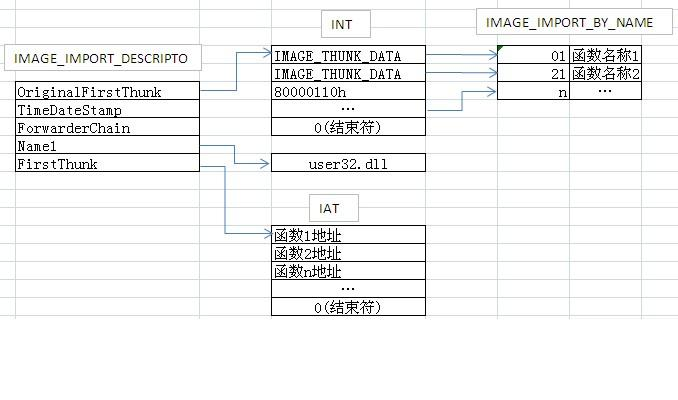
PE文件加载后:
 相关的两个数据结构:
相关的两个数据结构:
1 | typedef struct _IMAGE_THUNK_DATA32 { |
输出导入表的过程:
1、定位导入表:
1 | 目录项目的第2个结构就是导入表 |
导入表结构中有若干个导入表,依靠最后的全0结构来判断结束
1 | 将RVA转换成FOA |
1 | sizeOf(IMAGE_IMPORT_DESCRIPTOR) 个 0 代表导入表结束 |
2、输出DLL名字
每个结构代表一个DLL
1 | typedef struct _IMAGE_IMPORT_DESCRIPTOR { |
3、遍历OriginalFirstThunk(INT)
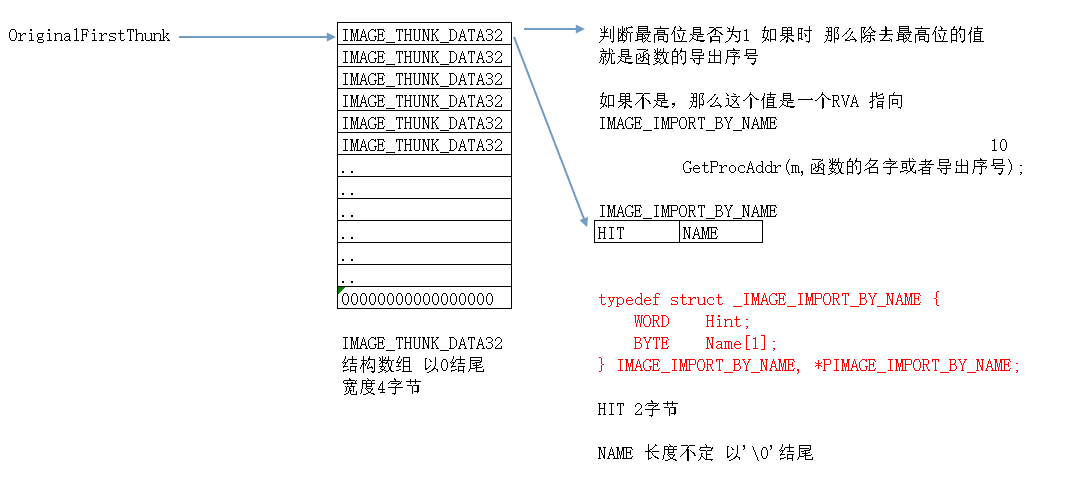
4、遍历FirstThunk(IAT)
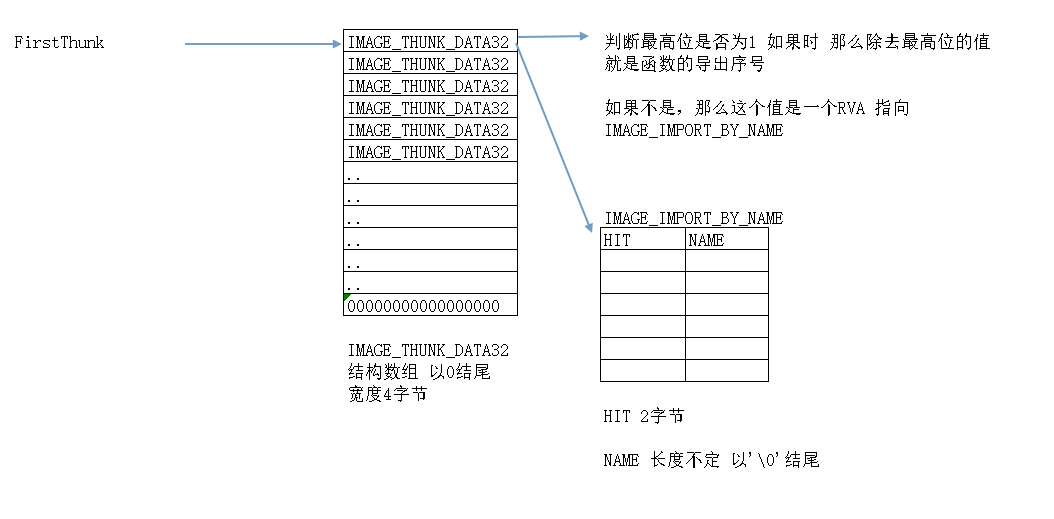
在没加载时,3和4中的数据是一样的
GetProcAddr()实际上就是根据DLL加载的地址去读取相应的导出表,通过序号或名字查找到真正的函数地址
注意:
在加载前,IAT表和INT表存储的数据完全一样,都指向同一个IMAGE_IMPORT_BY_NAME表。
编译的时候,每加载一个DLL,就会生成一个对应的导入表,所以导入表的数量不确定,并不是唯一的。
结尾标志都是全0的同结构