代码复用
代码复用
在C中,代码复用主要有三种实现方式:
- 静态链接库
- 动态链接库
- 使用.def 导出
静态链接库
特点
- 利用静态函数库编译成的文件比较大,因为整个 函数库的所有数据都会被整合进目标代码中;我们常用的printf、memcpy、strcpy等就来自这种静态库
- 一旦静态库发生了变化,程序如果要用则就要重新编译
使用方法
创建静态链接库
1、在VC6中创建项目:Win32 Static Library
2、在项目中创建两个文件:xxx.h 和 xxx.cpp
xxx.h文件:
1 |
|
PE结构解析
首先上图(非常细致):
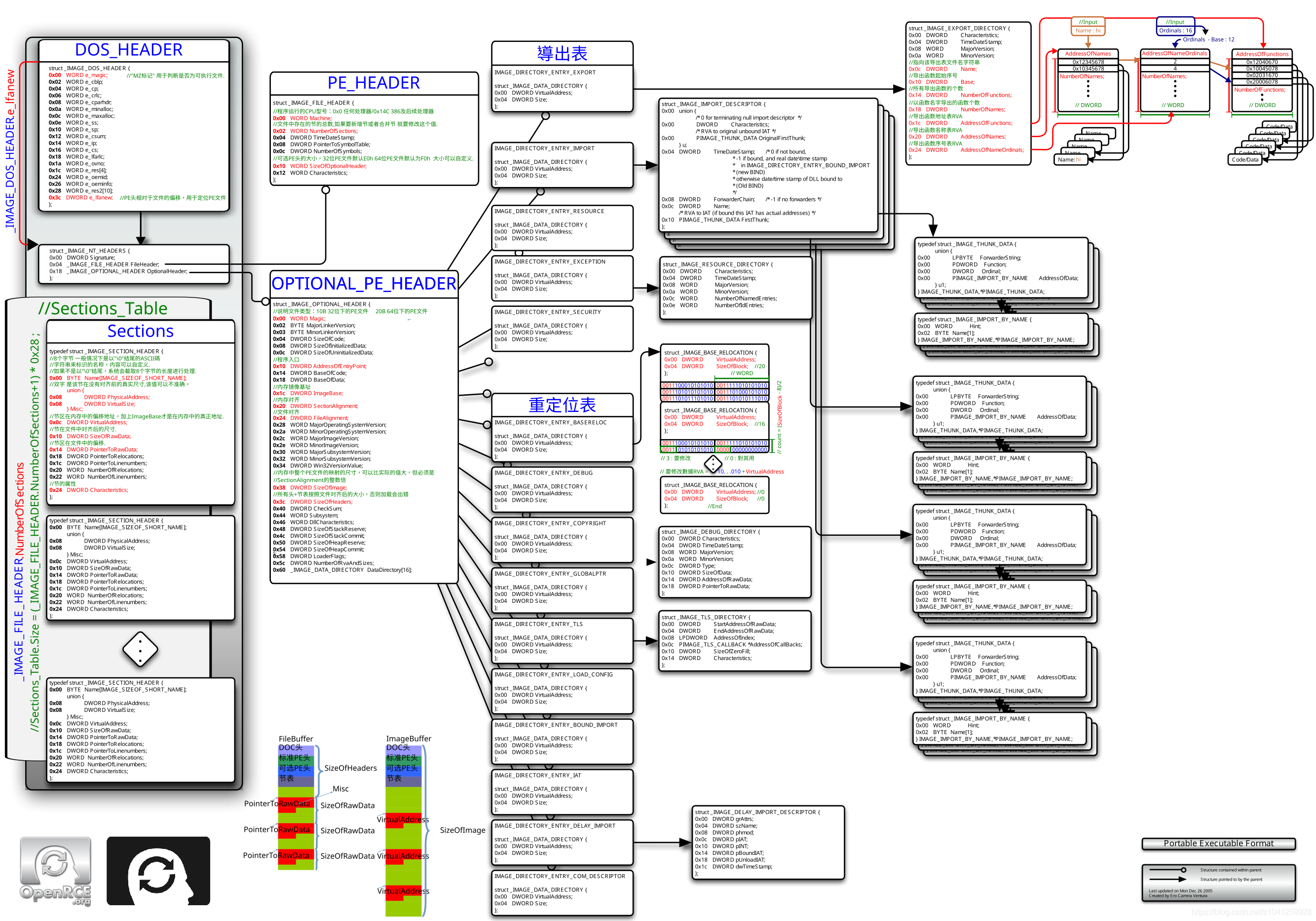
相对重要的概念
| 名称 | 描述 |
|---|---|
| 地址 | 是“虚拟地址”而不是“物理地址”。为什么不是“物理地址”呢?因为数据在内存的位置经常在变,这样可以节省内存开支、避开错误的内存位置等的优势。同时用户并不需要知道具体的“真实地址”,因为系统自己会为程序准备好内存空间的(只要内存足够大) |
| 镜像文件 | 包含以EXE文件为代表的“可执行文件”、以DLL文件为代表的“动态链接库”。镜像(直接“复制”到内存,有“镜像”的某种意思),就是指pe文件经过拉伸后在内存中的整个文件 |
| RVA | Relatively Virtual Address。偏移(又称“相对虚拟地址”)。相对镜像基址的偏移。 |
| 节 | 节是PE文件中代码或数据的基本单元。原则上讲,节只分为“代码节”和“数据节”。 |
| VA | Virtual Address PE文件中的指令被装入内存后的地址VA(虚拟地址)=IB(基址)+RVA(偏移) |
| 装载地址 | 也叫基地址,Image Base PE装入内存时的基地址,默认情况下,EXE文件在内存中的基地址是0x00400000,DLL文件是0x10000000. 由编译器决定 |
| 文件偏移 | FileOffset、RAWOffset 即文件存储在磁盘(而非内存)时的相对文件头(0位置)的位置,起始值就是0。用winhex打开一个pe文件,看到的就是文件偏移 |
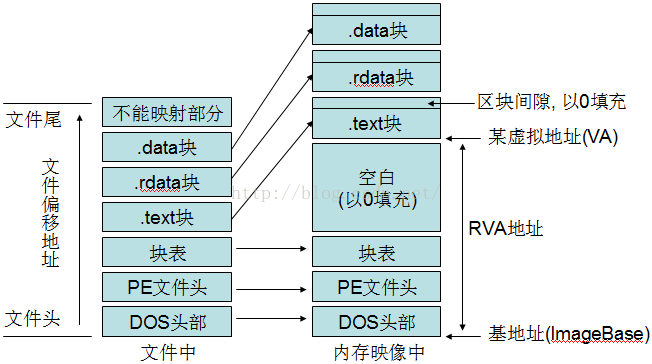
32bit和64bit的PE文件格式大同小异,64bit的只不过修改了PE格式的少数几个域,大部分情况下,操作PE的代码可以同时适用32bit和64bit
EXE和DLL都是PE格式文件 只不过其中的标识位不一样
博客迁移
新博客的ip地址
博客部署在github,访问起来实在是太慢了,(虽然写的也不频繁。。),于是放到了国内服务器上,方案是hexo+nginx。
ip: 39.108.177.97(还没有买域名)
整个迁移的过程
配置服务器
配置nginx
首先切换成root用户
安装nginx
1 | apt intsall nginx |
启动nginx
1 | service nginx start |
测试是否安装成功
1 | nginx -V |
能看到版本号就说明安装成功了
建立git仓库
通过建立一个git用户来进行git操作
新建git用户
1 | adduser git |
然后建立裸仓
1 | cd /home/git |
然后将本地上的ssh公钥复制到/home/git/.ssh/authorized_keys文件
reverse_box_wp
reverse_box
这是一道攻防世界的逆向进阶中的一道题目。攻防世界里少给了一些条件,道中一开始看的时候,就非常懵逼,然后找到原题后看到提示:
挑战描述
$ ./reverse_box $ {FLAG}
95eeaf95ef94234999582f722f492f72b19a7aaf72e6e776b57aee722fe77ab5ad9aaeb156729676ae7a236d99b1df4a reverse_box.7z
这个二进制文件的用法是把你输入的第二个命令行参数当flag,然后程序给出一堆十六进制的数。
但是如果输入的第二个命令行参数相同,程序输出的十六进制数也可能不相同。
除去查壳等一系列工作,将文件拖入IDA中进行分析,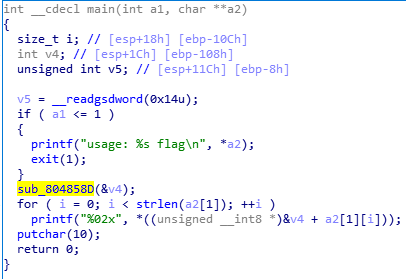
发现了相同输入但是不同输出的原因:程序里有一个随机函数,以时间作为种子: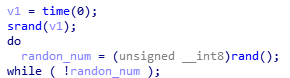
然后通过这个随机数构造了一个数组,然后按照输入的flag,对应输出数组中的值.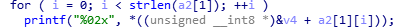
gdb写脚本爆破
1 | set $i=0 |
迷宫问题
迷宫问题的特点:
1.在内存中布置一张“地图”
2.将用户输入限制在少数几个字符范围内
3.一般只有一个迷宫入口和一个迷宫出口
布置的地图可以由可显字符组成,也可以单纯用不可显的十六进制值进行表示,可以将地图直接组成一条非常长的字符串,或是一行一行分开布置。如果是一行一行分开布置的话,因为迷宫一般都会比较大,所以用于按行布置迷宫的函数会明显重复多次。
xctf 逆向新手区最后一题—maze
除去查壳等操作,直接拖入IDA中进行分析: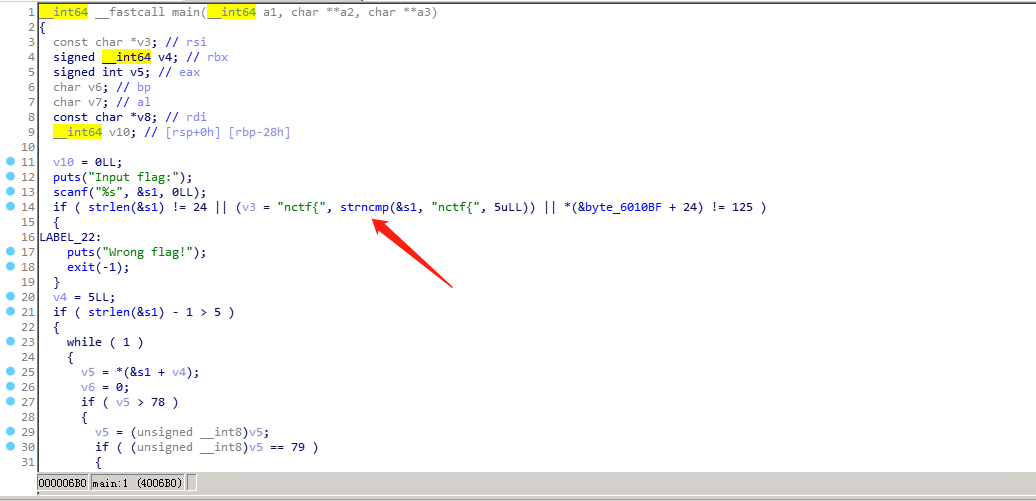
发现字符串比较,结论是flag必须是以nctf{开头。
接下来发现四个判断,每次判断后都进入相应的函数: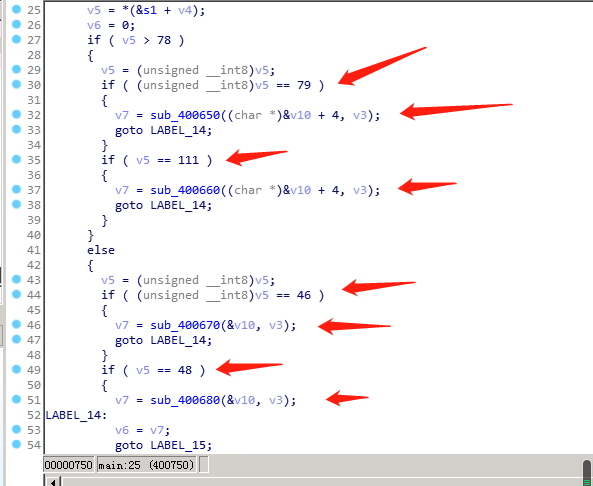
而每个函数又都非常简单,无非是加加减减,还有判断是否大于零小于八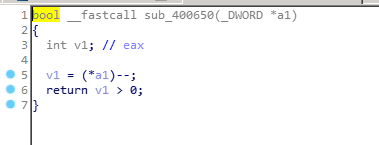
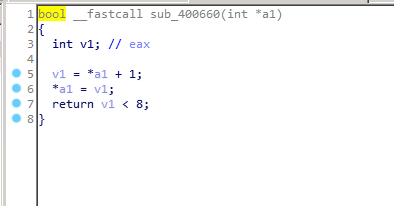
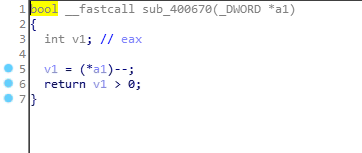
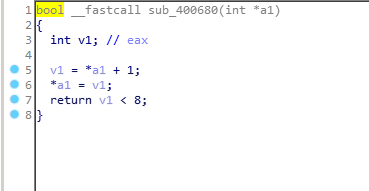
如果没有见过maze问题的话,确实会有一点懵,如果见过的话,去字符串里看看就会发现一些有用的东西: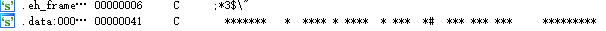
再根据大于零小于八的限制,就可以发现,这一串字符串实际上可以组成一个8*8的迷宫
然后是通过’.’,’0’,’o’,’O’来确定上下左右的移动。
那么最后走出迷宫就可以得到flag:nctf{o0oo00O000oooo..OO}
当涉及到的迷宫问题比较难解决的时候,或许可以通过深度搜索和广度搜索来解决迷宫问题,就比如CTF Wiki上的以到例题:
函数部分和上题差不多,但是迷宫很大:可能一个个去找会烦死。
参考资料:
https://ctf-wiki.github.io/ctf-wiki/reverse/maze/maze-zh/
XCTF_PWN新手区
搭建环境
由于是第一次接触PWN,所以先在网上找了些环境搭建的博客看看,然后发现这篇很好很全,推荐:https://www.jianshu.com/p/1476f38e3aa3
这次题目主要用到的工具有:
pwntools:用python开发的一个ctf框架和漏洞利用开发库
ROPgadget:好像只用了一次,用来搜索”/bin/sh”字符串所在的位置
IDA:嗯,必备的,不说了
checksec:查看可执行文件属性的工具
checksec包含的保护机制
1)CANNARY(栈保护)
栈溢出保护是一种缓冲区溢出攻击缓解手段,当函数存在缓冲区溢出攻击漏洞时,攻击者可以覆盖栈上的返回地址来让shellcode能够得到执行。当启用栈保护后,函数开始执行的时候会先往栈里插入cookie信息,当函数真正返回的时候会验证cookie信息是否合法,如果不合法就停止程序运行。攻击者在覆盖返回地址的时候往往也会将cookie信息给覆盖掉,导致栈保护检查失败而阻止shellcode的执行。在Linux中我们将cookie信息称为canary。
2)FORTIFY
3)NX(DEP)
NX即No-eXecute(不可执行)的意思,NX(DEP)的基本原理是将数据所在内存页标识为不可执行,当程序溢出成功转入shellcode时,程序会尝试在数据页面上执行指令,此时CPU就会抛出异常,而不是去执行恶意指令。
4)PIE(ASLR)
一般情况下NX(Windows平台上称其为DEP)和地址空间分布随机化(ASLR)会同时工作。
内存地址随机化机制(address space layout randomization),有以下三种情况
0 - 表示关闭进程地址空间随机化。
1 - 表示将mmap的基址,stack和vdso页面随机化。
2 - 表示在1的基础上增加栈(heap)的随机化。
可以防范基于Ret2libc方式的针对DEP的攻击。ASLR和DEP配合使用,能有效阻止攻击者在堆栈上运行恶意代码。
5)RELRO
设置符号重定向表格为只读或在程序启动时就解析并绑定所有动态符号,从而减少对GOT(Global Offset Table)攻击。RELRO为” Partial RELRO”,说明我们对GOT表具有写权限。
checksec这一部分来自这
正文
写了pwn新手区的八道题,由于时间仓促,来不及写writeup,于是就总结一下遇到的几种情况.
格式化字符串漏洞
讲这个之前,必须先了解栈和栈帧.
这里的漏洞是指printf的格式化漏洞.以前学的C语言讲,printf(“%d %d”,a,b)格式化输出要和变量对应,输出几个就要有几个对应的变量,但是实际上,没有对应的变量时,printf也能执行,它会自动从栈中读取.
而格式化输出的参数里,有一个”%n
“,它的作用是将它前面的字符个数写入当前栈顶指针所指向的地址对应的存储空间,还一个就是”%?$n”,就是将%前面的字符个数写入[ESP+?]所指向的内存空间.
那么,如果我们知道我们要修改的变量相对于栈顶指针的位置,那我们就可以对其进行修改了.
寻找偏移量的话,一般是利用输入函数的漏洞,输入包含”%p-%p-%p-%p-%p”的字符,来实现地址的打印,从而发现变量的相对位置.
写shellcode
详见第七题string
shellcode就是在程序漏洞处执行的特定代码.
写shellcode的时候要注意先设置目标机的参数
1 | context(os='linux',arch='amd64') |
然后获取shellcode的话就是获取执行system(“/bin/sh”)汇编代码所对应的机器码,通过python语句
1 | asm(shellcraft.()) |
获得
gets的漏洞
gets()是一个极其不安全的函数,因为它没有限定读入的字符个数.第八题就利用到了这一点,直接将生成伪随机数的种子给覆盖,然后程序生成的随机数变成一串已知的数字序列,从而触发”cat flag”的条件,获得flag
整数溢出漏洞
cnss_recruit
easy_flat
本题涉及代码混淆,具体是控制流平坦化
直接拖入IDA,F5:

然后查看流程框图:
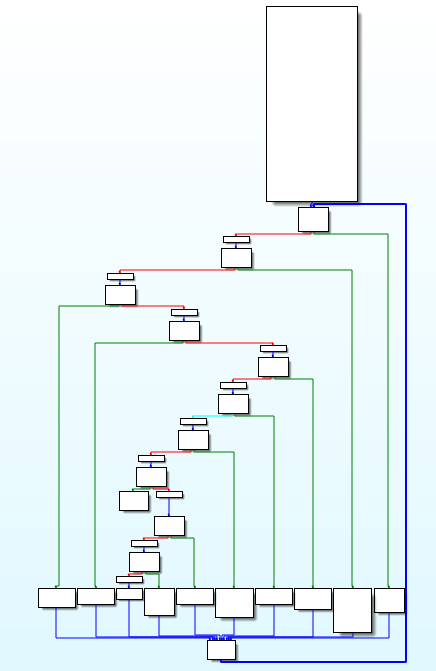
经过晴宇哥的指点以后,我去搜了一些关于控制流平坦化的资料:
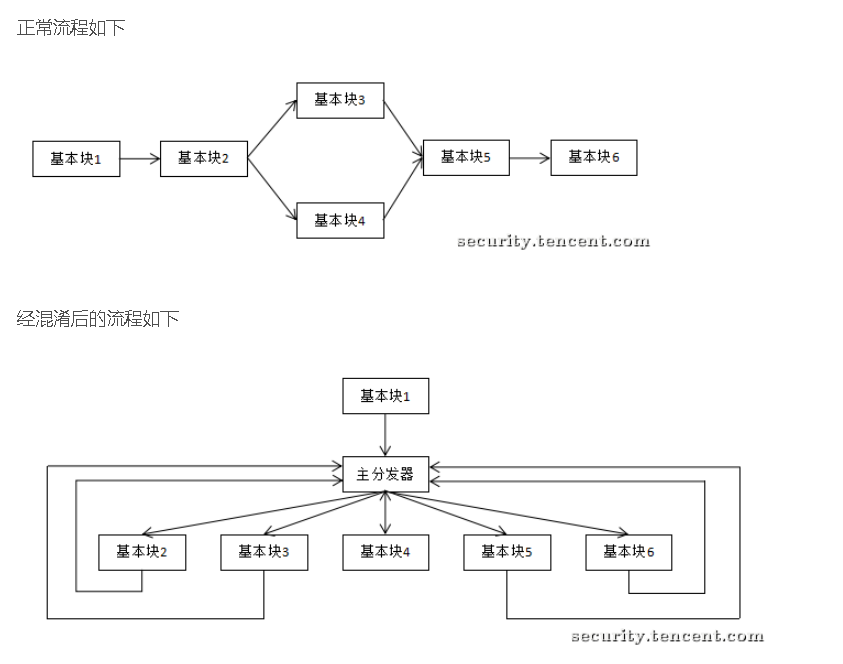
实际上,只是控制流程的方式变了,这道题相对简单,我们还是能够看出流程来。
继续分析伪代码,先看到一个长得像scanf的函数,把里面参数重命名为input,然后继续往下看,发现其中存在一个字符串比较的过程,点击查看被比较的另一个字符串后,发现是这样的字符串,长得很像flag,应该就是flag被加密后的形式.

现在就是要去寻找加密的方式,查看input被引用的地方,发现也就是这:
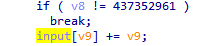

cnss-re-snake
刚看到这道题目的时候有点懵,因为从来没有用过CheatEngine进行逆向调试,题目提示可以使用CE进行调试,于是我就先学了一波CE的教程,具体过程前文已经写了。
但是,学完使用CE后,仍然不会逆,于是跑去请教炮王,炮王不愧是炮王,虽然没帮我拿到Flag,但是给我演示了静态调试和动态调试的过程,受益匪浅。
下面是逆的过程。
首先把文件拖到ida里进行静态调试。找到主函数。
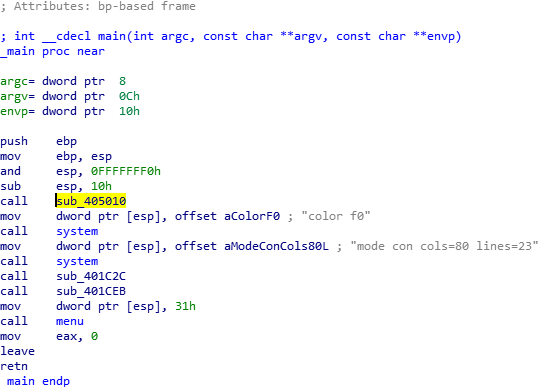
这一步不需要看伪代码也能看出,就是六个函数的调用。
我们这时候打开游戏来看,首先看到有个菜单,根据C语言的经验,应该至少有一个switch语句和死循环。然后我们开始游戏一看,游戏就是个贪食蛇的游戏,提示是这样:
我们先用CE去搜得分,确实搜到了,但是正如提示的那样,直接修改是没有用的。
接着我们发现游戏失败时有对话框弹出,我们可以先尝试下搜索字符串。搜索到后查看调用:
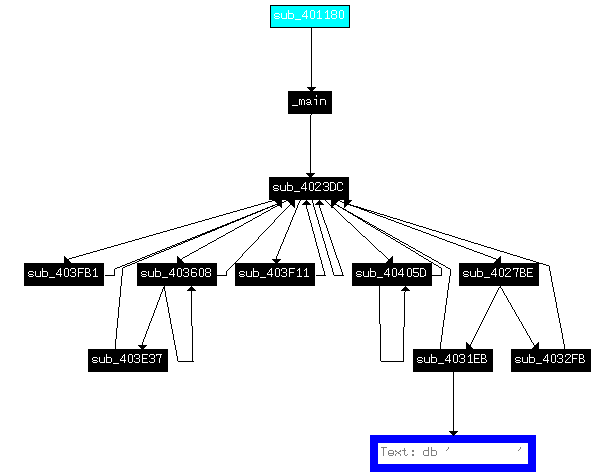
发现这个字符串在 sub_4031EB 函数里被调用,我们搜索进入这个函数,发现里面全是一些失败的提示消息:

这里将这个函数名改成fail,以便于我们的理解。
fail函数被sub_4027BE函数调用,而这个函数有两个分支,其中一个是fail,那另一个应该就是succeed了吧.找到进去一看,应该就是了,但是整个函数很复杂,可能就是计算出flag的过程.我们查看下那个可疑的 sub_4027BE函数.查看之后,发现一个很熟悉的printf函数:
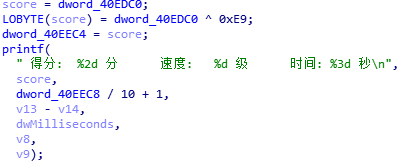
这个函数告诉我们,得分对应的参数就是显示出来的分数,我们将它命名为score.
往上一看,发现这个score的值是dword_40eDC0赋予的,这个也许就是存储得分的真正位置.
那就继续看dword_40eDC0这个什么时候被访问,往下看我们发现这样一段代码:

这里面调用的函数正是我们之前怀疑的succeed函数,他们原来是在这里py交易的!
仔细看这段代码,发现出题人是将真正的得分的低八位和0xE9H相与,判断相与后的值是否大于265.
抓住这一点我们就可以拿到Flag了,
这时候进行动态调试,这里用的是CE.
我们要先找到得分对应的真正位置,将其改成265^0xE9的值就好了.
还是先搜索得分,然后找出访问了这个得分的这段代码,发现长这样:

因为此时我们就在整个函数里面了,所以那个变量应该就在附近,我们看到483这个数字很可疑,因为1对应, —————————-我们找到这个变量的地址,将其修改成483,

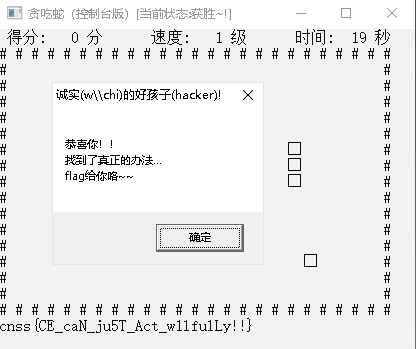
再去游戏里面,就发现通关拿到flag了,flag是: cnss{CE_caN_ju5T_Act_w1lfulLy!!}
本题总结:
1、之前没有好好利用IDA去了解整个程序的主体就直接去动态调试,导致整个过程思路不明确,效率极低。
2、使用IDA进行调试时,可以用快捷键N修改变量名,函数名,这样有利于整个代码的阅读和理解。
Confusion
直接拖入IDA,F5

看到这个像scanf一样的函数,心里就有个底了。sub_426980 这个应该就是读入的函数.
进入下个函数查看,简单分析后,发现应该是判断输入的flag的长度,如果长度是32个字符,才能够进入下个函数.
再下面的函数,是用来判断输入的flag的前五位是否是”cnss{“,如果不是的话,程序也会直接跳出.
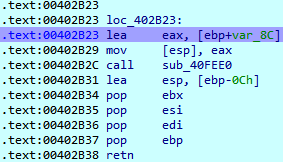
再接下来看到一个比较复杂的函数,里面有很多次循环,应该是一个加密的函数.函数很复杂,直接逆出来的话,难度相当大.这时候要采用动态调试的方法,在函数执行的时候把flag找出来.
直接在函数返回之前下好断点,在寄存器里就找到了flag

本题总结
1.IDA是真的好用
2.加密函数很复杂的时候,动态调试很顶
Surprise
下断方式总结
现在就目前我知道的下断点的方法进行总结下
1、根据API下断点
根据API下断点有两种方法,一种是用Ctrl+G,然后输入想要断下的API,这个时候相关调用了API函数的地址就会变色,但是这样下的断点有时候没有用。
另一种根据API下断点的方式使用Ctrl+N,然后查看程序调用的所有API,然后键入想要断下的API(这个搜索栏有点奇怪,居然显示在OD的顶部),选中后F2下断就可以了。
2、字符串断点
嗯,,这种方法在能搜到字符串的时候很有用,但是搜不到的时候你就自求多福吧。
操作起来非常简单,就是直接搜,不知道是Ascii还是Unicode就用智能搜索,搜到之后,选中然后回车,这时候可能和关键代码比较近了。
3、内存断点
内存端点就是跟踪关键数据的断点。
感觉这种断点和Cheat Engine的模式有点像.
下断的方法就是,在内存区域选中一段关键数据,就有点像CE里面你搜索到的关键数据,然后右键点击断点,出现内存访问和内存写入两个选项,顾名思义,选择内存访问时就是当你选中的这段数据被调用时,程序就会被断下来,而内存写入时则是当这个数据被修改时程序会被断下来,用过CE的话,就应该会发现这两个下断的方式和CE里面查找是什么指令访问或者写入了这块数据很相像.
这个下断的方式就很牛逼了,因为这样可以很容易找到关键代码部分hhh.
然后这个下断方式有一个小技巧,就是如果已知一些数据,可以直接Alt+M,然后在这里面搜索一直的数据,然后下断.比如有个程序的序列码是由你输入的ID生成的,那么这个时候,你输入的ID就可以直接搜索,这样得到的信息量就非常多.
4、硬件断点
emm,本菜鸡还没遇到过。。。